GPT-Image-2 绘图教程
GPT-Image-2 是 OpenAI 于 2026 年 4 月发布的新一代图像生成模型,支持最高 2K 分辨率、强可控的图像内文字渲染、以及多图编辑。可通过 Clauddy 的 OpenAI 兼容 /v1/images/generations 接口调用。
Playground 在线体验(最简单)
无需写任何代码,直接在 Clauddy 网页端即可生成图片:
- 进入 Clauddy 操练场(左侧菜单点击 操练场)
- 在「模型」下拉框中选择
gpt-image-2 - 在底部输入框输入你的提示词(如「画一只可爱的猫咪坐在月亮上」),点击发送
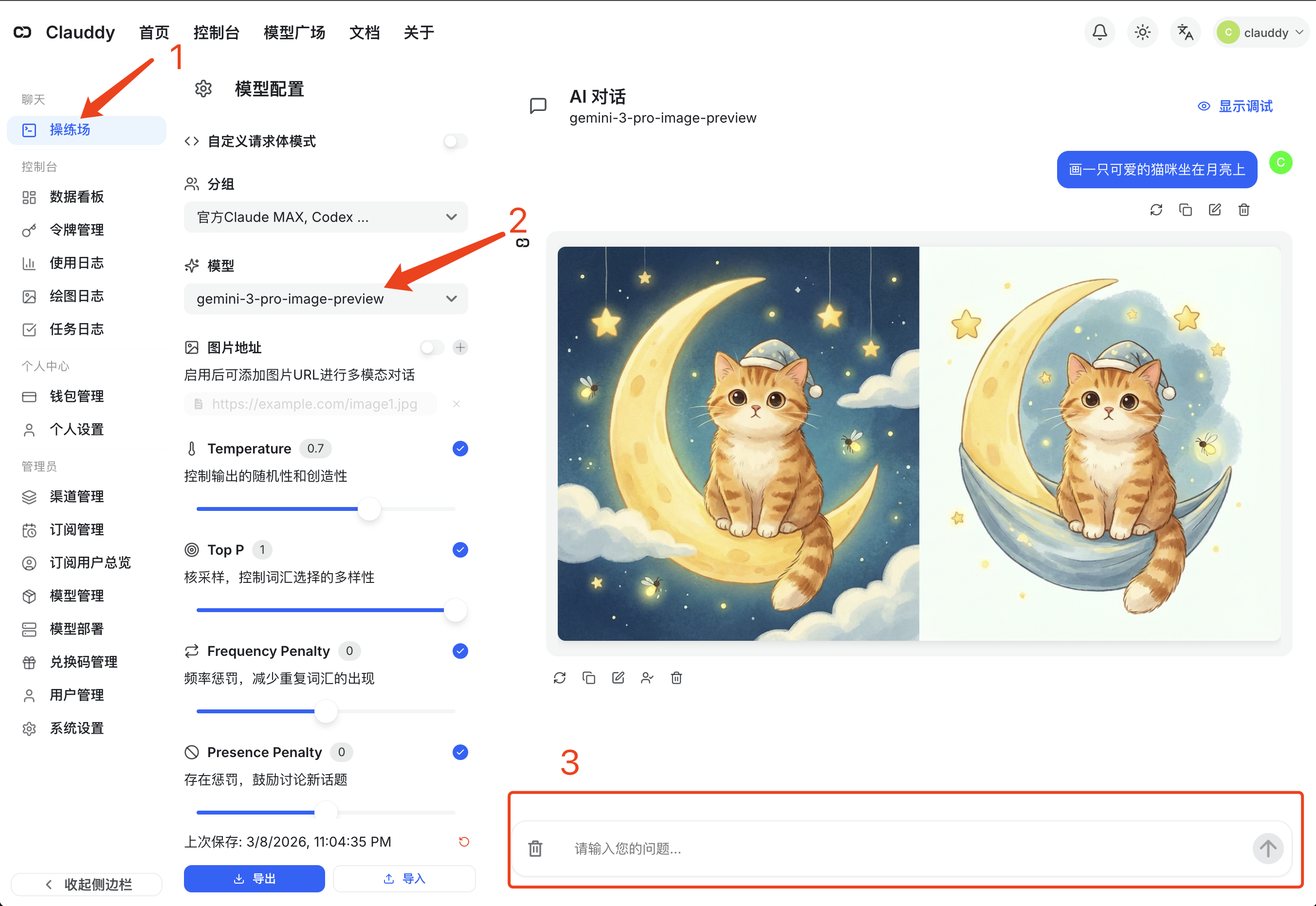
生成的图片会直接显示在对话区域,可以右键保存。
命令行测试(无需安装客户端)
最快的验证方式 —— 一行 curl + Python 解码 base64:
TOKEN="sk-you...oken" # 替换为你的 Clauddy 令牌
curl -sS https://clauddy.com/v1/images/generations \
-H "Authorization: Bearer $TOKEN" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-image-2",
"prompt": "一只可爱的猫咪坐在月亮上,数字插画风格",
"size": "1024x1024",
"n": 1
}' \
| python3 -c "import sys,json,base64; open('output.png','wb').write(base64.b64decode(json.load(sys.stdin)['data'][0]['b64_json']))" \
&& echo "已保存 output.png"执行后会在当前目录生成 output.png,效果示例:

关于响应格式
gpt-image-2 始终返回 base64(b64_json 字段),不支持 response_format=url。这与 DALL·E 系列不同,需要客户端自己解码。
API 调用(开发者)
模型信息
- 模型名称:
gpt-image-2 - 接口:
POST https://clauddy.com/v1/images/generations(文生图) - 编辑接口:
POST https://clauddy.com/v1/images/edits(图生图,multipart/form-data) - 响应格式: 始终
b64_json - 耗时: 1024×1024 约 30–60 秒,2K 可达 1–2 分钟(请把客户端超时设到 300 秒以上)
主要参数
| 参数 | 取值 | 说明 |
|---|---|---|
model | "gpt-image-2" | 必填 |
prompt | 字符串,最长约 32000 字符 | 必填,支持中英文 |
size | "1024x1024" / "1536x1024" / "1024x1536" / "2048x2048" / "auto" | 默认 auto |
quality | "low" / "medium" / "high" / "auto" | 默认 auto |
n | 1–10 | 一次生成几张 |
background | "transparent" / "opaque" / "auto" | 透明背景需 output_format=png 或 webp |
output_format | "png" / "jpeg" / "webp" | 默认 png |
Python 示例
import base64
from openai import OpenAI
client = OpenAI(
api_key="sk-you...oken",
base_url="https://clauddy.com/v1"
)
resp = client.images.generate(
model="gpt-image-2",
prompt="一只可爱的猫咪坐在月亮上,数字插画风格",
size="1024x1024",
quality="high",
n=1,
)
with open("output.png", "wb") as f:
f.write(base64.b64decode(resp.data[0].b64_json))
print("已保存 output.png")图生图 / 编辑(multipart)
/v1/images/edits 接口接受一张或多张输入图(最多 16 张),按提示词进行编辑、风格迁移或多图融合。注意:请求体是 multipart/form-data,不是 JSON。
curl 一键编辑
TOKEN="sk-you...oken"
curl -sS https://clauddy.com/v1/images/edits \
-H "Authorization: Bearer $TOKEN" \
-F "model=gpt-image-2" \
-F "image[][email protected]" \
-F 'prompt=把这只猫的项圈换成红色,并给它戴一副小圆墨镜,其它部分保持不变' \
-F "size=1024x1024" \
| python3 -c "import sys,json,base64; open('edited.png','wb').write(base64.b64decode(json.load(sys.stdin)['data'][0]['b64_json']))" \
&& echo "已保存 edited.png"编辑前后对比(输入:上一节生成的月亮上的猫;提示词:加红色项圈 + 小圆墨镜):
| 编辑前 | 编辑后 |
|---|---|
|  |
提示词写法
- 明确说"保持其它部分不变",避免模型把整张图重画
- 想保留构图就描述"同样的姿势/角度/背景"
- 要换风格就用"以 XXX 风格重绘这张图"
Python 编辑
import base64
from openai import OpenAI
client = OpenAI(
api_key="sk-you...oken",
base_url="https://clauddy.com/v1"
)
with open("input.png", "rb") as f:
resp = client.images.edit(
model="gpt-image-2",
image=f,
prompt="把这只猫的项圈换成红色,并给它戴一副小圆墨镜,其它部分保持不变",
size="1024x1024",
)
with open("edited.png", "wb") as f:
f.write(base64.b64decode(resp.data[0].b64_json))
print("已保存 edited.png")多图融合 / 风格迁移
最多可传 16 张图作为输入,常用于"把 A 的内容用 B 的风格画出来"、"把 A 和 B 的元素融合"等场景:
curl -sS https://clauddy.com/v1/images/edits \
-H "Authorization: Bearer $TOKEN" \
-F "model=gpt-image-2" \
-F "image[][email protected]" \
-F "image[]=@style_reference.png" \
-F 'prompt=以第二张图的水彩风格重绘第一张图中的主体' \
-F "size=1024x1024" \
| python3 -c "import sys,json,base64; open('fused.png','wb').write(base64.b64decode(json.load(sys.stdin)['data'][0]['b64_json']))"局部修改(mask 蒙版)
如需只修改图片的某个区域,可以传一张 PNG 蒙版(透明区域 = 要修改的位置):
curl -sS https://clauddy.com/v1/images/edits \
-H "Authorization: Bearer $TOKEN" \
-F "model=gpt-image-2" \
-F "image[][email protected]" \
-F "[email protected]" \
-F 'prompt=在蒙版区域画一只飞翔的鹦鹉' \
-F "size=1024x1024" \
| python3 -c "import sys,json,base64; open('inpaint.png','wb').write(base64.b64decode(json.load(sys.stdin)['data'][0]['b64_json']))"| 参数 | 说明 |
|---|---|
image[]=@文件 | 输入图(最多 16 张,传多个即可) |
mask=@文件 | 可选蒙版,透明区域为修改范围 |
input_fidelity | "high" / "low",对原图的忠实度,仅 edits 接口可用 |
prompt | 描述如何编辑 |
推荐客户端
不同客户端对图像生成接口的支持差异较大,以下按推荐度排序:
🥇 Open WebUI — 配置最简单
原生支持图像生成引擎,在管理后台填入:
ENABLE_IMAGE_GENERATION = true
IMAGE_GENERATION_ENGINE = openai
IMAGES_OPENAI_API_BASE_URL = https://clauddy.com/v1
IMAGES_OPENAI_API_KEY = sk-you...oken
IMAGE_GENERATION_MODEL = gpt-image-2
IMAGE_SIZE = 1024x1024聊天界面点击图片按钮即可生图,体验最干净。
🥈 Cherry Studio — 桌面端,UI 精致
自带尺寸 / 质量 / 数量选择器。配置要点:在 API 地址末尾加一个 #(如 https://clauddy.com/v1/images/generations#),否则 Cherry Studio 会自动把路径改写成 /chat/completions。模型名手动填 gpt-image-2。
🥉 Chatbox — 跨平台,需手动覆盖路径
Chatbox 默认走 /chat/completions,所以要在「自定义提供商」中:
- 选择 自定义 提供商类型
- API 路径手动改为
/v1/images/generations - 超时时间设为 ≥ 360 秒
- 模型名填
gpt-image-2
Chatbox 的局限
由于 /v1/images/generations 是无状态接口,无法做"再把猫的项圈改红"这样的多轮编辑。需要多轮迭代时建议用 Playground 或 Cherry Studio。
选择哪个绘图模型?
| 场景 | 推荐 |
|---|---|
| 写实风格、商业海报、产品图、图内文字渲染 | GPT-Image-2 |
| 创意场景、艺术风格、角色一致性、二次元 | Nano Banana Pro(Gemini) |
| 透明背景 PNG / WebP | GPT-Image-2(原生支持 background=transparent) |
| 多轮"改一下这里"对话式编辑 | Nano Banana Pro(chat 接口天然支持多轮) |
两者各有优势,建议同一提示词分别生成对比效果。